
A ‘simple’ GitHub Issue
A user of my previously abandoned grad-school electrodynamics solver opened a GitHub Issue. Normally I have no choice but to ignore these due to lack of time, but thanks to advancements in agentic coding I’ve been able to revisit hacking on my long lost projects.
The problem:
FileNotFoundError: [Errno 2] No such file or directory: 'C:\Users\AppData\Local\Temp\tmpdd_1rhu9/TMATFILES/Infotmatrix.dat'The user is running MiePy in a Windows environment, and the Infotmatrix.dat file cannot be found.
This is a runtime failure, where an output file from a compiled Fortran binary failed to materialize.
This could be for many reasons, and there’s probably a simple fix to get this working properly.
Instead I took this as an opportunity to try something more ambitious and interesting.
Fortran Code in MiePy
This issue immediately reminded me of my struggles with the Fortran code when I was writing MiePy. MiePy is a C++/Python electrodynamics solver I authored for solving Maxwell’s Equations for a collection of spherical particles. The Fortran code was included to compute particle T-matrices, which extends the solver to non-spherical particles. The Fortran code and algorithm are attributed to A. Doicu, T. Wriedt, and Y. Eremin: “Light Scattering by Systems of Particles”, Berlin, Heidelberg: Springer-Verlag, 2006.
My original approach was to directly include the NFM-DS source code in MiePy:
AdditonTh.f90 Interp.f90 Proces2.f90 TLAY.f90
Allocation.f90 MachParam.f90 Proces3.f90 TMATRIX.f90
allocation.mod MatrixOp.f90 Random.f90 TMULT.f90
BesLeg.f90 MatrixQ.f90 SCT.f90 TMULT2SPH.f90
Check.f90 MatrixSolv.f90 SCTAVRGSPH.f90 TMULTSPH.f90
derived_parameters.mod MatrixTrans.f90 SVWF.f90 TMULTSPHREC.f90
EFMED.f90 Parameters.f90 TAXSYM.f90 TNONAXSYM.f90
GeomLib.f90 parameters.mod TCOMP.f90 TPARTSUB.f90
GeomTrans.f90 PostProces1.f90 TINHOM.f90 TSPHERE.f90
IncCoeff.f90 PostProces2.f90 TINHOM2SPH.f90
InputOutput.f90 PostProces3.f90 TINHOMSPH.f90
Integr.f90 Proces1.f90 TINHOMSPHREC.f90subprocess.run.
The binary creates various output files, including the Infotmatrix.dat file, which can then be parsed and stored in a C++ Eigen matrix.
Converting Legacy Fortran to Modern C++
I never liked having to wrap the Fortran code in this way, or including Fortran code at all. It complicates the build and distribution process, and the subprocess call can cause issues on different platforms, as evidenced by this GitHub issue. I recall wanting to rewrite this code in C++ while in grad school, but I couldn’t justify the time it would cost. And that was a good software engineering principle too: don’t reinvent the wheel! Take existing working code, slap on a Python subprocess call and file parser, shove the output bits into Eigen and call it a day.
But today, in 2026, suddenly reinventing the wheel is nearly free, even at 47,000 lines of numerical Fortran code. Let’s see how a team of agents can convert the important subset of this Fortran code into about 3,000 lines of modern C++. This is an absolutely overkill solution to the original problem, but surprisingly not out of reach and the codebase is better for it.
Using a Claude Agent Team
We’re in good fortune thanks to A. Doicu, T. Wriedt, and Y. Eremin implementing the original Fortran code. We have a working implementation to test against, and LLMs excel at tool calls and iterating until tests pass. I first attempted this in a single agent using plan mode, but ran into an issue of running out of context. The Fortran code is quite dense, and it was challenging to get a proper rewrite to fit within one context window, or be broken up into multiple phases.
So I reached for the recently released Agent Teams. The idea was to have 3 agents to guide the migration:
- A C++ expert: this agent is responsible for writing C++ code to replace the Fortran code
- A Fortran expert: this agent is the steward of the Fortran code context, and challenges the C++ Agent on correctness
- The main orchestrator agent: ensure the C++ agent is working towards a solution compatible with MiePy that passes all tests
Here’s the prompt:
let’s launch an agent team to work on JOH-324
- as the main agent, you should orchestrate and understand the work. Review the current code base, git diff, and linear issue. You will delegate to your agent team what to work on.
- one agent will operate as the fortran expert. @src/miepy/tmatrix/nfmds is their responsibility. This is the old way of computing tmatrix through a fortran binary, using DS algorithm with and without extended precision
- one agent will operate as the C++ expert. @cpp/src/tmatrix/ contains c++ code that is meant to replace the fortran code. The C++ agent is trying to achieve a cleaner C++ interface that replicates the same capabilities as the fortran one. The fortran agent will challenge the C++ one on correctness
Your job is to make sure these agents work towards the goals of a C++ interface that can replace the fortran one, without sacrificing correctness and ensuring the C++ interface is clean and compatible with the rest of the codebase
Here are the 3 agents in action:
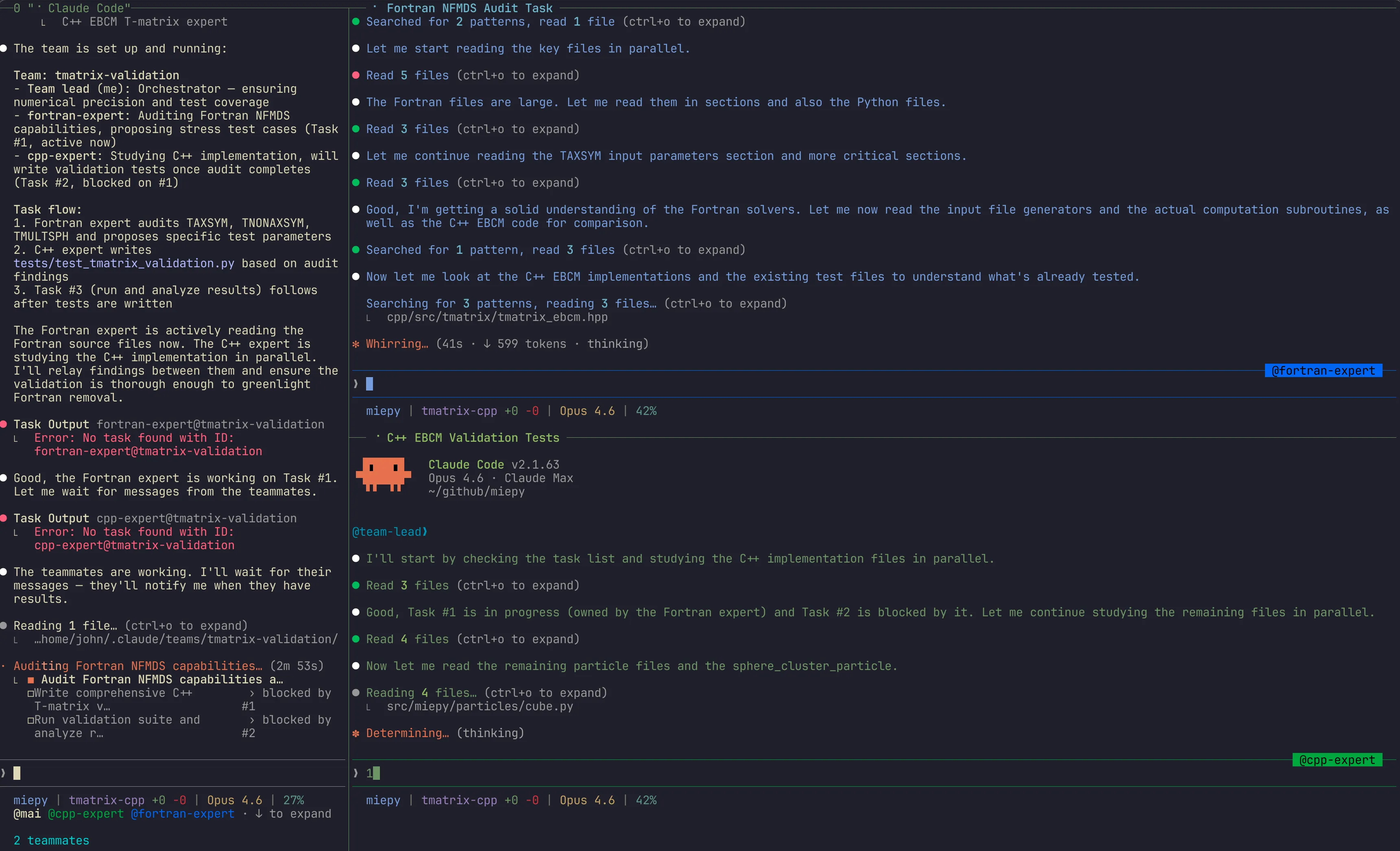
This was able to achieve the full migration within the agent’s three context windows. The C++ agent did end up running out of context towards the end, and the orchestrator took over to finish the migration.
Pushing for Correctness
After completing that first pass comes the important question: is the C++ code actually correct? How do we test for correctness? We have a suite of existing tests that pass under the new C++ implementation, but there is still some concern around edge cases.
I tried a second agent team pass post-implementation to focus on correctness and edge cases, such as high aspect ratio particles that require extended precision. Here’s the prompt:
We want to prepare phasing out all Fortran code in this codebase (the tmatrix nfmds solver). Before doing so we want to be absolutely sure that the C++ implementation is ready to replace the Fortran implementation. To assess that, let’s spawn an agent team:
- you as the orchestrator, ensuring that the goal is kept in mind, numerical precision is obtained, and tests verify our expectations
- a fortran teammate that acts as an expert on @src/miepy/tmatrix/nfmds/ implementation
- a C++ teammate that acts as an expert on the C++ conversion
You should push the C++ teammate to test:
- correctness on supported particle type tmatrix
- pushing certain limits, such as using extended precision on highly oblate or prolate particles (aspect ratio up to 20) You should push the Fortran teammate to challenge the C++ one on correctness
Now that a rewrite is not in order, the agents were able to focus on review and edge cases. The agent’s key findings:
Key Findings
- The C++ implementation fully covers all particle types the Fortran supported for standard use: spheroid, cylinder, rounded cylinder, ellipsoid, regular N-hedral prism, sphere cluster
- Extended precision works to 20:1 aspect ratios for prolate spheroids with __float128
- Unitarity verified with correct formula T + T - 2TT = 0 (convention S = I - 2T): machine precision for Mie sphere, < 1% for non-spherical particles
- Fortran-only features NOT in C++ (acceptable gaps):
- Chiral materials (niche)
- Uniaxial anisotropic materials (niche)
- Mishchenko convergence procedure (not needed, rcond diagnostics provide alternative)
- File geometry input (niche)
- User-defined DS positions (niche)
- Known EBCM limitation: Oblate metallic particles at double precision show negative absorption at AR≥3. This is fundamental to EBCM (same in Fortran). Extended precision resolves it.
Recommendation: The C++ implementation is ready to fully replace Fortran.
The double agent team pass and passing test suite is very promising. And the 47,000 lines of Fortran has been reduced to 3,000 lines of C++ (only 12,000 lines of Fortran were relevant for the conversion).
The scientist in me still feels we need to test more. I feel uneasy about the idea of just pushing this agent generated code as a replacement of the Fortran code. I didn’t write it myself after all! How can I trust its scientific accuracy?
Verifying Against FDTD Simulations
Numerical agreement with the Fortran code is promising and perhaps sufficient to call it a day. They don’t match exactly due to differences in floating point math, but the tolerances look good.
As an extra test, I asked Claude to conduct a suite of simulations using MIT’s Meep Finite-Difference Time-Domain (FDTD) solver. This is a grid-based solver to Maxwell’s equations that can model particles of any geometry. If I can get agreement between Meep and MiePy across a large range of geometries and particle properties, I would feel better about publishing this C++ implementation. Numerical comparisons are shown below and show excellent agreement across all categories.
Axisymmetric Particles
Axisymmetric particles are those that have symmetry along the azimuthal angle . The T-matrix surface integral can be analytically evaluated along and numerically evaluated as a single integral along the polar angle . Axisymmetric particles include spheroids (prolate and oblate), and cylinders. To test off-axis illumination, the cylinder was tilted.




Note that Meep is not fully converged, especially at longer wavelengths. Grid-based methods require fine resolutions and longer runtimes for long wavelengths to decay.
Non-Axisymmetric Particles
Non-axisymmetric particles lack the symmetry, and require a full double surface integral to evaluate the T-matrix. Examples include cubes, ellipsoids, and prisms.



Extreme Aspect Ratio — Extended Precision
A 20:1 aspect ratio oblate spheroid is a test for a difficult edge case.
The T-matrix method requires extended precisions (complex numbers with 2X-f128 precision).
At large aspect ratios, the integral is evaluated using multiple origin sources to improve convergence.
Performance Comparison
Another concern is the runtime performance of the C++ implementation vs the Fortran implementation. Below are plots of runtime to evaluate a T-matrix (smaller is faster).
T-Matrix Geometries — Standard Precision
In standard precision, the runtime performance is nearly identical for axisymmetric particles. For non-axisymmetric particles, the C++ code is 2X faster - Claude found an opportunity to reduce the number of integral calls by a factor of 2!
The C++ implementation is also parallelized using OpenMP, speeding up axisymmetric T-matrix evaluation ~2X and non-axisymmetric evaluation ~8X on a 16-core/32-thread CPU. The Fortran code never supported parallel execution.


T-Matrix Geometries — Extended Precision
For extended precision, Fortran takes a slight edge on axisymmetric particles, but remains slower for non-axisymmetric particles. Parallel execution is even more efficient with extended precision in the C++ implementation.


Lmax Sweep — Standard Precision
We can also measure performance at variable lmax, the parameter that controls the size of the T-matrix.
Larger particles (relative to light wavelength) require higher lmax for accuracy.
Non-axisymmetric particles are a clear win for C++.
Axisymmetric show Fortran code starting slower at lower lmax but faster at higher lmax.


Lmax Sweep — Extended Precision
Similar story with extended precision.


Code Comparison
Below are side-by-side comparisons of key routines between the original Fortran NFM-DS solver and the C++ replacement, showing how the agent team translated core algorithms.
Q-Matrix Surface Integration
Integrates mixed products of vector spherical wave functions over the particle surface to build Q11 and Q31 matrices.
ki = k * ind_ref
sign = 1._O
if (index1 == 3 .and. index2 == 1) sign = - 1._O
f = sign * im * 2._O * k * k
do iparam = 1, Nparam
Nintl = Nintparam(iparam)
do pint = 1, Nintl
param = paramG(iparam,pint)
pondere = weightsG(iparam,pint)
call elem_geomAXSYM (TypeGeom, Nsurf, surf, param, iparam, &
r, theta, phi, dA, nuv)
zc = ki * r
zl = cmplx(k * r,0.0,O)
call mvnv_m (index1, index2, chiral, DS, zl, zc, zcl, zcr, kc, ki, &
kil, kir, r, theta, m, Nrank, Nmax, NmaxC, NmaxL, &
zRe, zIm, mv3, nv3, mv1, nv1)
fact = f * dA * pondere
call matQ_m (m, NmaxC, NmaxL, chiral, perfectcond, mirror, &
ind_ref, fact, mv3, nv3, mv1, nv1, nuv, A, nap, map)
end do
end docomplex_t f = complex_t(sign_val, 0) * complex_t(0, 1)
* complex_t(Real(2), 0) * complex_t(k_real * k_real, 0);
std::vector<std::vector<Real>> paramG, weightsG;
geom.quadrature_points(Nint, mirror, paramG, weightsG);
for (int iparam = 0; iparam < Nparam; iparam++) {
int Nintl = static_cast<int>(paramG[iparam].size());
for (int pint = 0; pint < Nintl; pint++) {
Real param = paramG[iparam][pint];
Real weight = weightsG[iparam][pint];
GeometryPoint<Real> pt = geom.evaluate(param, iparam);
Real r = pt.r, theta = pt.theta;
Real dA = pt.dA;
Real nuv_r = pt.n_r, nuv_theta = pt.n_theta;
complex_t zl(k_real * r, 0);
complex_t zc = k_int * complex_t(r, 0);
// Select localized or distributed SVWFs
if (use_ds && index1 == 3) {
svwf_distributed<Real>(3, kc, r, theta, zRe, zIm, ...);
} else {
svwf_localized<Real>(index1, zl, theta, ...);
}
complex_t fact = f * complex_t(dA * weight, 0);
// inline mixed product accumulation (see next section)
}
}Fortran delegates SVWF selection to mvnv_m and accumulation to matQ_m; C++ inlines both. Fortran passes geometry as integer TypeGeom + array surf; C++ uses a polymorphic AxialGeometry<Real> object with evaluate() returning a structured GeometryPoint. Fortran supports chiral media; C++ omits it (unused in miepy).
Q-Matrix Element Accumulation
Accumulates the four 2x2 blocks (magnetic/electric x magnetic/electric) of the Q-matrix at each quadrature point.
do i = 1, NmaxL
ni = abs(m) + i - 1 ! (or i for m=0)
mvl = mv3(:,i); nvl = nv3(:,i)
do j = 1, NmaxC
nj = abs(m) + j - 1
mvc = mv1(:,j); nvc = nv1(:,j)
s = (-1._O)**(ni + nj)
v1 = mixt_product (nuv, mvc, nvl)
v2 = mixt_product (nuv, nvc, mvl)
A(i,j) = A(i,j) + (v1 + ind_ref * v2) * fact
if (mirror) A(i,j) = A(i,j) + s * (v1 + ind_ref * v2) * fact
if (m /= 0) then
v1 = mixt_product (nuv, nvc, nvl)
v2 = mixt_product (nuv, mvc, mvl)
A(i,j+NmaxC) = A(i,j+NmaxC) + (v1 + ind_ref * v2) * fact
! ... blocks (1,0) and (1,1) similarly
end if
end do
end dofor (int i = 0; i < NmaxL; i++) {
int ni = (std::abs(m) == 0) ? (i + 1) : (std::abs(m) + i);
complex_t mvl[3] = {mv3[0][i], mv3[1][i], mv3[2][i]};
complex_t nvl[3] = {nv3[0][i], nv3[1][i], nv3[2][i]};
for (int j = 0; j < NmaxC; j++) {
int nj = (std::abs(m) == 0) ? (j + 1) : (std::abs(m) + j);
complex_t mvc[3] = {mv1[0][j], mv1[1][j], mv1[2][j]};
complex_t nvc[3] = {nv1[0][j], nv1[1][j], nv1[2][j]};
Real s = ((ni + nj) % 2 == 0) ? Real(1) : Real(-1);
complex_t v1 = mixt_product<Real>(nuv_r, nuv_theta, mvc, nvl);
complex_t v2 = mixt_product<Real>(nuv_r, nuv_theta, nvc, mvl);
A(i, j) += (v1 + n_rel * v2) * fact;
if (mirror) A(i, j) += complex_t(s, 0) * (v1 + n_rel * v2) * fact;
if (m != 0) {
v1 = mixt_product<Real>(nuv_r, nuv_theta, nvc, nvl);
v2 = mixt_product<Real>(nuv_r, nuv_theta, mvc, mvl);
A(i, j + NmaxC) += (v1 + n_rel * v2) * fact;
if (mirror) A(i, j + NmaxC) -= complex_t(s, 0) * ...;
// ... blocks (1,0) and (1,1) similarly
}
}
}Same algorithm in both languages. Fortran uses (-1._O)**(ni+nj) (exponentiation); C++ uses modular arithmetic ((ni+nj) % 2 == 0). C++ passes normal components nuv_r, nuv_theta separately (2D for axisymmetric); Fortran passes nuv(3) array (phi component unused).
T-Matrix Extraction from Q Matrices
Computes via LU decomposition with matrix equilibration.
! Build Q31 and Q11 for azimuthal mode m
call matrix_Q_m (..., 3, 1, ..., a, Nrank, Nrank) ! Q31 -> a
call matrix_Q_m (..., 1, 1, ..., b, Nrank, Nrank) ! Q11 -> b
! Solve: b = b * a^{-1} (T-matrix stored in b)
call LU_SYSTEM (a, 2*Nrank, 2*Nrank, b, 2*Nrank, 2*Nrank, 2*Nmax)
! --- Inside LU_SYSTEM (MatrixSolv.f90:156-172) ---
! Computes x = b * a^{-1} via transpose trick:
call transpose (a, nap, map, n)
call transpose (b, nbp, mbp, n)
call equilibrate (a, nap, map, n, n, row, column)
call LUDCMP (a, nap, map, n, indx, d)
do j = 1, n
do i = 1, n
c(i) = b(i,j) * row(i) ! apply row scaling
end do
call LUBKSB (a, nap, map, n, indx, c)
do i = 1, n
b(i,j) = c(i) * column(i) ! apply column scaling
end do
end do
call transpose (b, nbp, mbp, n)// Non-DS mode: T_m = Q11 * Q31^{-1}
Matrix Q31 = assemble_Q_m<Real>(geom, 3, 1, ...); // [2*Nmax, 2*Nmax]
Matrix Q11 = assemble_Q_m<Real>(geom, 1, 1, ...); // [2*Nmax, 2*Nmax]
// T_m = Q11 * Q31^{-1} via: lu(Q31^T).solve(Q11^T)^T
double rcond;
Matrix T_m = equilibrated_lu_solve<Real>(
Matrix(Q31.transpose()), Matrix(Q11.transpose()), rcond).transpose();
// --- Inside equilibrated_lu_solve (tmatrix_linalg.hpp) ---
auto [row_scale, col_scale] = equilibrate_matrix<Real>(A_eq);
Eigen::PartialPivLU<Matrix> lu(A_eq);
rcond_out = static_cast<double>(lu.rcond());
Matrix B_scaled = diag(row_scale) * B_orig;
Matrix X = lu.solve(B_scaled);
// Iterative refinement (up to 3 iterations)
for (int iter = 0; iter < itmax; iter++) {
Matrix residual = B_scaled - A_eq * X;
// Check componentwise backward error
if (berr_max <= eps) break;
Matrix dx = lu.solve(residual);
X += dx;
}
// Unscale: X(i,:) *= col_scale(i)Both use the transpose trick to compute via a standard linear solve. Fortran solves column-by-column with explicit LUDCMP/LUBKSB; C++ uses Eigen’s PartialPivLU which solves all columns at once. C++ adds iterative refinement with componentwise backward error checking and returns rcond for diagnostics.
Lines of Code
A comparison of lines of code in each implementation across different modules.
| Category | Fortran | C++ |
|---|---|---|
| Core EBCM solvers | ||
| Axisymmetric driver | TAXSYM (2,133) | tmatrix_ebcm.cpp (588) |
| Non-axisymmetric driver | TNONAXSYM (1,632) | tmatrix_ebcm_nonaxial.cpp (427) |
| Q-matrix assembly | MatrixQ (1,068) | (inlined in solvers) |
| Math / special functions | ||
| Bessel & Legendre | BesLeg (1,777) | tmatrix_special.cpp (474) |
| SVWFs | SVWF (1,599) | tmatrix_svwf.cpp (269) |
| Quadrature | Integr (557) + Interp (378) | (in geometry.hpp) |
| Geometry & linear algebra | ||
| Particle shapes | GeomLib (2,037) | tmatrix_geometry.hpp (675) |
| Matrix solving | MatrixSolv (1,057) | tmatrix_linalg.hpp (206) |
| Infra | Params+Mach+Alloc (375) | tmatrix_types.hpp (193) |
| Bindings | — | tmatrix_pyb.cpp (545) |
| Total | 12,613 | 3,598 |